 Book a Demo
Book a Demo
Engineering | From engineering
The 3X performance gap: Why your Agentforce prompts need batch testing
Discover why single prompt testing fails in production. Learn how batch testing revealed a 3x performance gap between AI models and the simple technique that boosted Agentforce speed without sacrificing quality.

Two seconds. That’s all it takes for a user to decide your AI assistant is too slow. We learned this after watching our perfectly-tested Salesforce prompt template crawl in production. What followed was a crash course in the performance gap that single tests hide and batch testing reveals.
The template testing trap
Agentforce prompt templates use named placeholders (like {{user_query}} and {{previous_question}}) that get replaced with real values each time. You can’t run a batch of inputs against the template in one pass. You must test each instance individually.
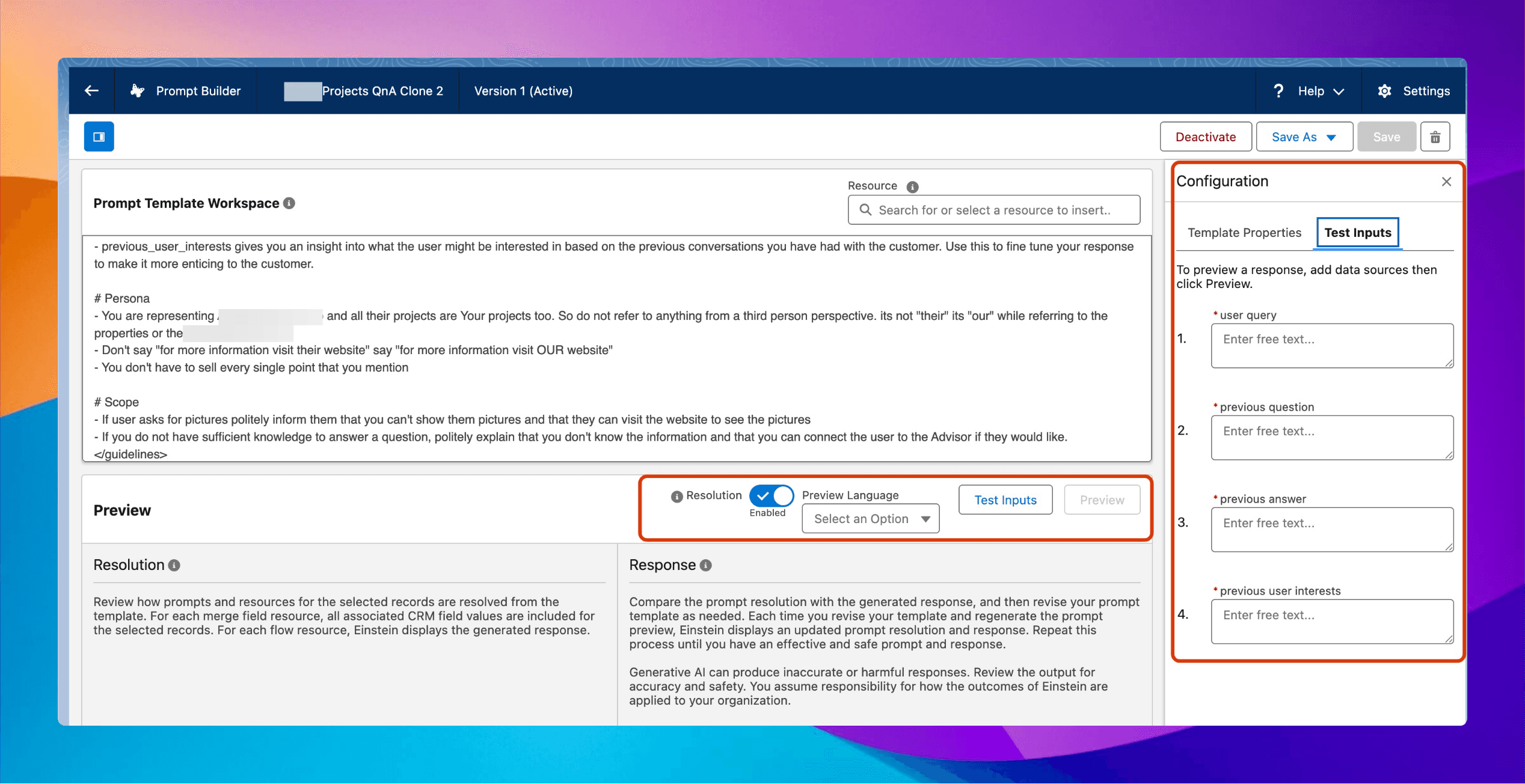
The native Prompt Builder interface in Salesforce makes this worse. You craft your prompt, hit “Preview,” see a decent response, and think, “Ship it!” But production is different. Latency variance, token limits, and model quirks combine to create a storm of inconsistency.
This isn’t theoretical. We recently discovered one of our implementations had latency swings so dramatic that users abandoned the feature before responses arrived. The culprit? Testing that failed to capture the variance that would later become painfully obvious in production.
Real numbers, real pain
Let me share a recent example. One of our implementation teams was dealing with persistent latency issues in a real estate listing assistant. The initial approach - testing each prompt template once or twice in isolation - painted a misleading picture.
When we finally ran comprehensive benchmarks with 100 samples of the same “4 bedroom in New York” prompt across different models, the results were sobering:
TLDR: The latency issues are sort of resolved 🎉
How?
4o VS 3.7 sonnet: Using the benchmarking tool, we can clearly see that 4o is at least 3x faster*Let that sink in.
A 3x performance difference that was completely invisible during standard testing.
The peculiar shape of prompt testing
The fundamental problem lies in how Salesforce’s prompt testing environment works. The standard flow is seductively straightforward: craft your prompt, check a single response, tweak, and repeat.
It’s like trying to evaluate a car’s reliability by driving it once around the block on a perfect spring day. Sure, it might feel great in that moment, but what happens in a rainstorm? During rush hour? After 50,000 miles?
We discovered this the hard way. The beautiful responses we saw in the Prompt Builder interface often deteriorated under production traffic pressure. Models that seemed responsive in testing would suddenly lag when hit with concurrent requests.
And token count - that invisible resource meter ticking away with every request - became a critical factor that single tests couldn’t reveal:
Prompt token optimisations:
The prompt has been significantly optimized, we now consume ~½ of the input tokens and ~⅓ of the output tokens compared to earlier.
However this did not have a significant impact on the overall latenciesDespite cutting our token usage by 50-67%, we still faced latency challenges. This counterintuitive result would never have surfaced without batch testing across multiple conditions.
Our testing approach
As an AI-native company, we solve problems like this by quickly building tools using AI. The Prompt Template Tester we built simulates reasonable production conditions. It allows us to:
-
Send dozens or hundreds of similar-but-varying prompts to the model
-
Track response times, token usage, and quality metrics
-
Compare performance across different model options
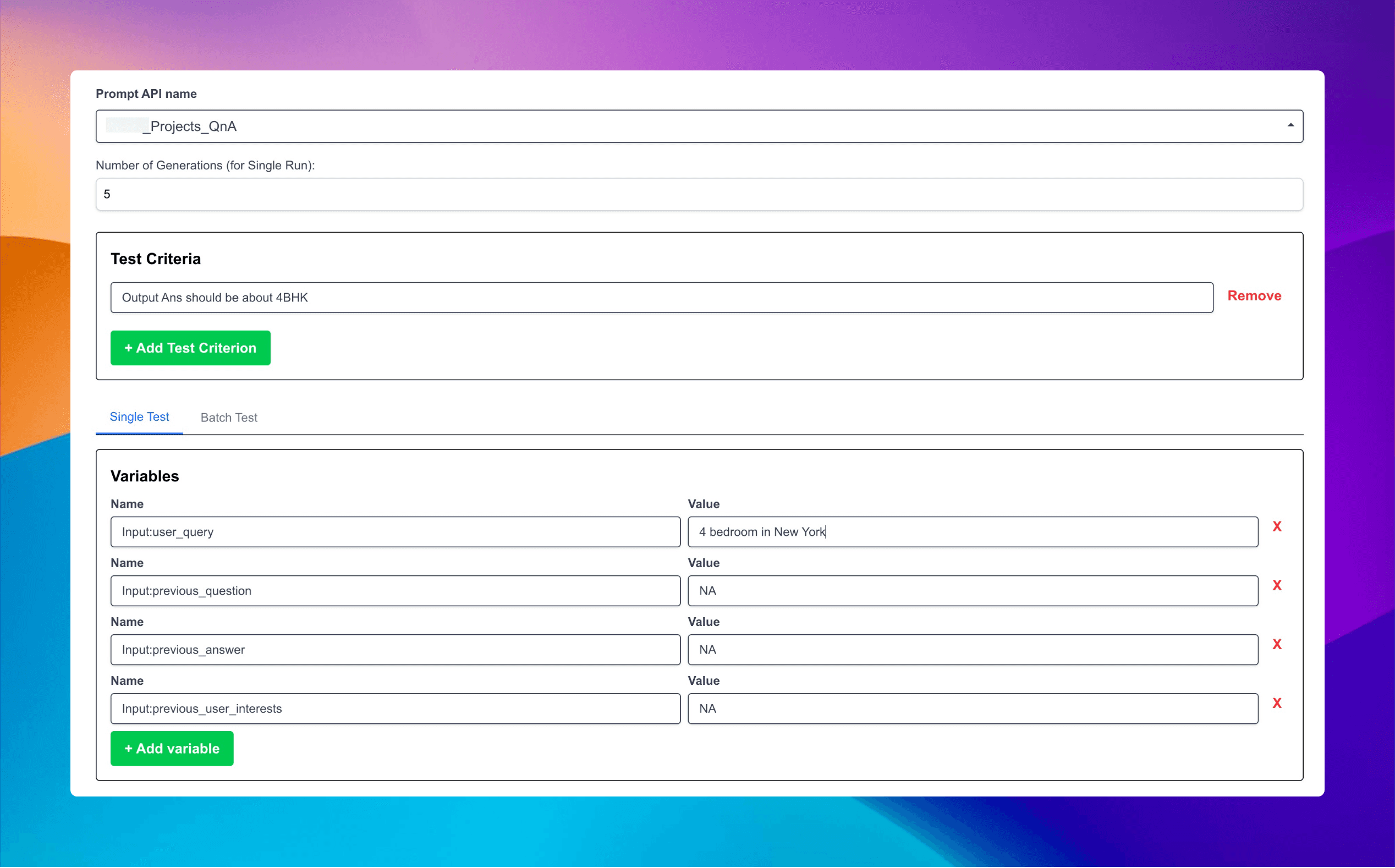
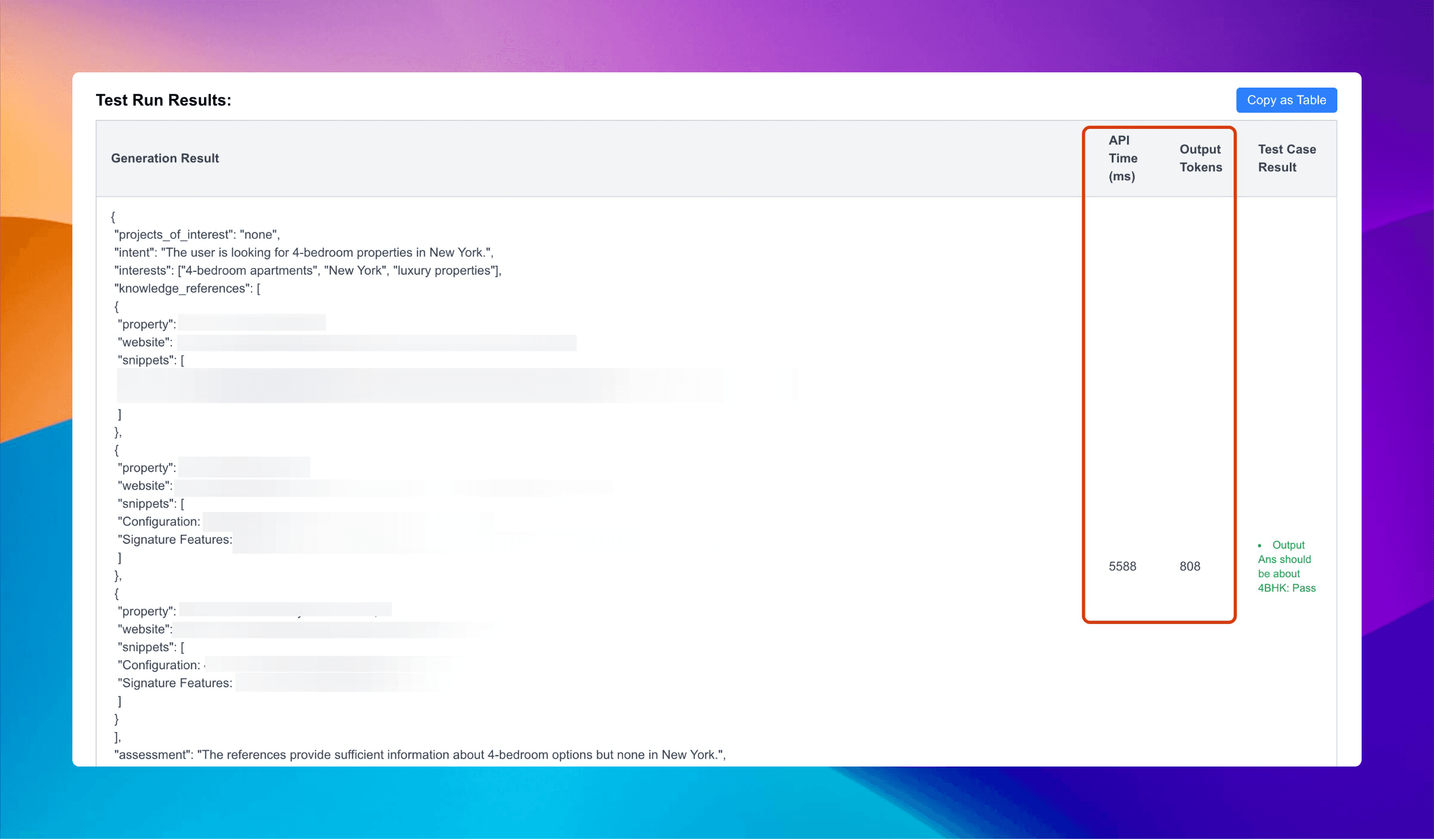
We started with 100 samples of our real estate query prompt. This gave us enough statistical significance to identify patterns without waiting days for results.
The insights were immediate and actionable. We could suddenly see the performance gap between Claude 3.7 Sonnet and GPT-4o with clarity. More importantly, we could quantify the tradeoffs between latency and response quality.
We now use this tool across all of our Agentforce implementations.
Token diet: Halving input, cutting output by two-thirds
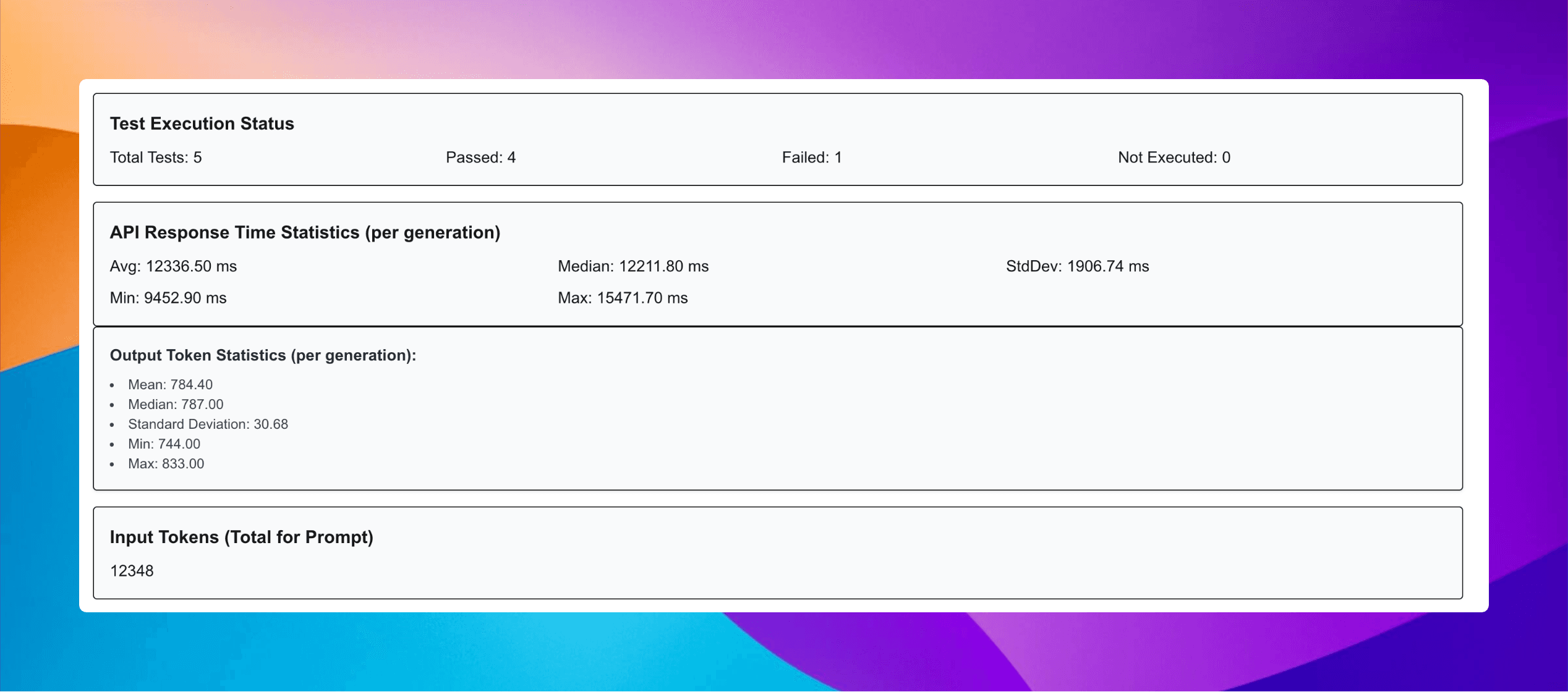
A key insight from our batch testing was the opportunity to dramatically reduce token usage. By running dozens of tests in parallel, we could quickly identify patterns in model responses that were using unnecessary tokens.
Our prompt engineer took a scalpel to the template, eliminating redundancies and tightening instructions. The results were significant:
-
Input tokens reduced by approximately 50%
-
Output tokens reduced by approximately 67%
The most surprising finding was that this token diet, while helping marginally, didn’t solve our latency issues. The model compute time still dominated the overall response time - an insight we would have missed without batch testing multiple variables simultaneously.
This led us to an even more important discovery.
The example effect
The breakthrough came from an elegantly simple idea: what if we used the higher-quality responses from the slower model to teach the faster model?
Dealing with 4o's poor responses:
I started providing Sonny's outputs to 4o as examples in the prompt. Now 4o is able to respond similarly to Sonny.By adding Claude 3.7 Sonnet’s outputs as examples in our prompts to GPT-4o, we achieved a best-of-both-worlds outcome:
-
The speed of the faster model (GPT-4o)
-
The response quality approaching that of the slower model (Claude)
This technique - what we call “the example effect” - has become a standard practice in our implementations. It’s a practical application of few-shot learning that delivers material improvements in production environments.
But we never would have discovered it without our batch testing approach.
Patterns that worked
Through painful trial and error, we’ve established some patterns that consistently improve our prompt template implementations:
-
Benchmark across models - Don’t assume performance characteristics from marketing materials. Test each model option with your actual prompts.
-
Measure what matters - Track not just average latency, but also 95th percentile latency, token usage, and response quality metrics.
-
Feed examples strategically - Use high-quality outputs from slower/better models as examples for faster/cheaper models.
-
Tokens aren’t the only factor - Cutting token count is the quickest win, but real speed improvements come from refining prompt complexity and choosing the right model.
What’s next
Our current batch testing approach has clear limitations. It’s still manual in many ways, requiring CSV preparation and result interpretation. The feedback loop between testing and implementation could be tighter. And we’re just beginning to explore automated quality scoring for responses.
But the core insight remains powerful: testing prompt templates one at a time is fundamentally insufficient for production-grade implementations.
As we continue to refine our approach, we’re focusing on:
-
Automating the generation of test cases from production patterns
-
Building more sophisticated comparison tools for response quality
-
Integrating batch testing directly into our CI/CD pipeline
At realfast.ai, we’ve come to see batch testing as non-negotiable for serious Agentforce implementations. The gap between what works in single tests and what works in production is simply too wide to bridge any other way.
Ready for enterprise-grade Agentforce?
Don’t let hidden performance gaps derail your AI initiatives. Partner with realfast.ai to implement robust, scalable, enterprise-grade Agentforce solutions that deliver on speed, reliability, and consistency. Contact us today to elevate your prompt performance and ensure production-ready success.